https://github.com/newnuu/ethics_classification.git
GitHub - newnuu/ethics_classification
Contribute to newnuu/ethics_classification development by creating an account on GitHub.
github.com
1. 데이터
data.txt
train 10004 건
test 1038 건
틀딱 할저씨들 왜케 낮에 술마시고 쳐돌아다님?,
술쳐마셨으면 한강가서 재기나 하지,
한순간이라도 맨정신이면 버티기 힘든 인생이라 그런가봄
화자1,"혐오","비난",
화자1,"혐오","비난","폭력",
화자2,"비난",
...
2-3개의 문장으로 이루어져 있는 문장 set
문장별 화자 정보,
레이블 : 혐오, 선정, 범죄, 욕설, 비난, 비도덕아님, 폭력, 차별 중 중복 가능
데이터 분석
- 문장의 길이는 대부분 20-30
- 60이 넘어가는 경우는 거의 없음
오류 데이터 처리
1. 라벨 비어있는 경우



원래 txt 파일 확인 결과 위 문장의 라벨에 잘못 들어가있는 경우로 판단 -> 문장에 맞게 선택하여 넣어줌
그 외 비도덕 아님과 다른 레이블이 함께 들어간 경우 삭제
2. train, test 데이터에 각각 1개씩 '기타'로 레이블링 된 데이터 포함 -> 삭제

오류 수정 후 csv 파일로 저장
data.csv

d_num : 대화 set 번호
데이터 분포 ( 전체 데이터 대비 각 레이블별 비율 )
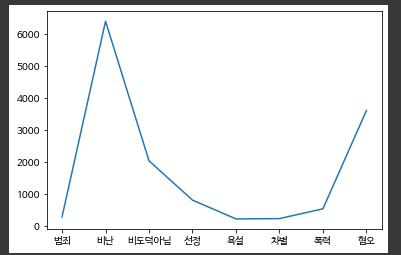

레이블 별 차이가 심하다
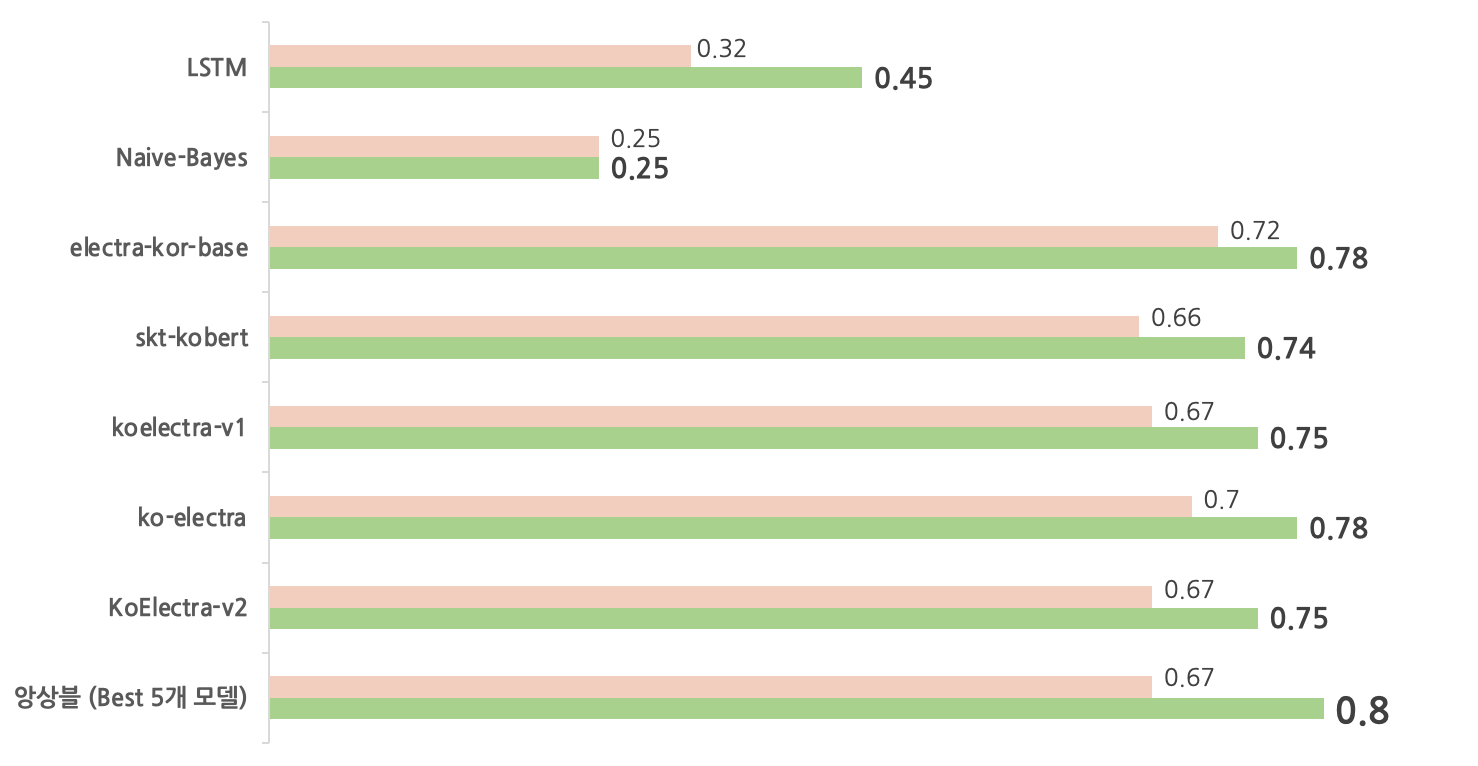
2. Model 1차 실험
- Naive bayse
-
CountVectorizer (word의 count로 벡터) 사용
- label 84개
- 원래 텍스트파일에 들어있던대로 "혐오, 비난", "비난, 욕설, 폭력" 등
- 8개의 label별 이진 분류
-
- LSTM (Bidirectional)
-
class LSTM(nn.Module): def __init__(self,dimension=128): super(LSTM,self).__init__() self.embedding = nn.Embedding(len(text_field.vocab),32) self.dimension = dimension self.lstm = nn.LSTM(input_size = 32,hidden_size = dimension,num_layers=1,batch_first = True,bidirectional = True) self.drop = nn.Dropout(p=0.5) self.fc = nn.Linear(2*dimension,1) def forward(self,text,text_len): text_emb = self.embedding(text) packed_input = pack_padded_sequence(text_emb, text_len.cpu(), batch_first=True, enforce_sorted=False) packed_output, _ = self.lstm(packed_input) output, _ = pad_packed_sequence(packed_output, batch_first=True) out_forward = output[range(len(output)), text_len - 1, :self.dimension] # 정방향 lstm의 마지막 hidden state out_reverse = output[:, 0, self.dimension:] # 역방향 lstm의 첫번째 hidden state out_reduced = torch.cat((out_forward, out_reverse), 1) text_fea = self.drop(out_reduced) text_fea = self.fc(text_fea) text_fea = torch.squeeze(text_fea, 1) text_out = torch.sigmoid(text_fea) return text_out - torchtext 이용하여 데이터셋 정의
- tokenize 단어 띄어쓰기로 함
- optimizer = optim.Adam(model.parameters(), lr=0.001)
- 따로 사전 훈련 임베딩을 사용하지 않고 Embedding layer 사용 ( 임베딩 차원도 32로 작음)
- nn.LSTM(input_size = 32,hidden_size = 128,num_layers=1,batch_first = True,bidirectional = True)
모델 epoch 범죄 혐오 선정 비도덕 아님 폭력 비난 욕설 차별 acc batch 32 LSTM 10 0.9519 0.6303 0.8848 0.8036 0.9359 0.6242 0.9739 0.9790 0.2184 batch 32 LSTM 20 0.7896 0.6092 0.8747 0.7806 0.8036 0.6333 0.9719 0.9729 0.1362 batch 64 LSTM 10 0.9339 0.5822 0.9248 0.8076 0.8918 0.6663 0.9810 0.9840 0.2224 batch 64 LSTM 20 0.9659 0.5832 0.9108 0.8026 0.9178 0.6533 0.9709 0.9739 0.1933 batch 64 LSTM 50 0.9699 0.6162 0.9108 0.7866 0.9238 0.6152 0.9800 0.9820 0.1462 batch 32 LSTM 10 84개 레이블 0.2214 batch 32 LSTM 20 84개 레이블 0.2425 0,1 개수 맞추기
acc (데이터 수)LSTM 50 0.7857 (56개) 0.5139 (720) 0.4845 (161) 0.4852 (406) 0.5607 (107) 0.4666 (718) 0.5116 (43) 0.4889 (45) - 각각의 점수는 높은데 합치면 낮음 ( 0의 비율이 크기 때문 )
- 각 레이블 별 0과 1의 개수를 맞춰서 돌렸을 때 -> 마지막 줄 ( 전체적으로 정확도 하락)
- 데이터 수가 적어서
- 84개의 레이블로 돌렸을 때도 대부분의 결과가 0으로 나옴
-
데이터 오버 샘플링 (https://d2.naver.com/helloworld/7753273 참고)
모든 레이블에 1인 데이터가 적으므로 0과 1의 비율이 비슷하도록 1인 데이터 추가 (중복) ('비난' 은 오버샘플링 하지 않음)
-> 혐오, 비도덕 아님, 비난 ( 원래도 어느정도 1의 비율이 높았던 레이블) 의 성능은 하락하였고,
나머지 1의 비율이 매우 적었던 데이터들의 정확도는 약간 상승
ELMO 임베딩
ELMO Embedding + Dense layer
모델 epoch 범죄 혐오 선정 비도덕아님 폭력 비난 욕설 차별 전체 acc
| epoch | 범죄 | 혐오 | 선정 | 비도덕 아님 | 폭력 | 비난 | 욕설 | 차별 | |
| LSTM | 10 | 0.9519 | 0.6303 | 0.8848 | 0.8036 | 0.9359 | 0.6242 | 0.9739 | 0.9790 |
| ELMo | 10 | 0.9689 | 0.6583 | 0.9289 | 0.7876 | 0.9429 | 0.6493 | 0.9749 | 0.9749 |
| ELMo 오버샘플링 |
10 | 0.9928 | 0.6576 | 0.9713 | 0.7142 | 0.9474 | 0.6313 | 0.9883 | 0.9822 |
비도덕 아님 <-> 나머지 7개의 레이블
- 전체적으로 성능 향상 !
화자데이터 활용
- 대화 세트별 모든 대화를 합쳐서 공통인 라벨을 붙이기
- 대화 세트별, 같은 화자의 문장을 합쳐서 레이블을 모두 합치기( 비도덕 아님 제외)
- 대화 세트별, 같은 화자의 문장들의 공통 레이블을 붙이기
외부 데이터 활용
- 한국어 욕설 데이터 (https://github.com/2runo/Curse-detection-data)
- 단순 욕설, 인종 차별적인 말, 정치적 갈등을 조장하는 말, 성적·성차별적인 말, 타인을 비하하는 말, 그 외에 불쾌감을 주거나 욕설로 판단되는 말 - True로 분류
- False 인 데이터만 비도덕 아님 데이터로 분류하여 추가 (약 3000건)
- Korean-hate-speech (https://github.com/kocohub/korean-hate-speech)
- contain_gender_bias, social_bias, hate 3가지 라벨이 모두 False, none, none인 데이터를 비도덕 아님 데이터에 추가
- 한국어 욕설 데이터 활용했을 때보다 성능 하락 -> 사용 안함
Pretrained Model 활용
- KoBert
- KoElectra
- Electra-kor-Base
| Model | Label 개수 | test_accuracy | max_length |
| electra-kor-base | 8 | 0.16377649325626203 | 64 |
| 7 | 0.7023121387283237 | 64 | |
| kobert | 8 | 0.569364161849711 | 64 |
| 7 | 0.6339113680154143 | 64 | |
| 8 | 0.5655105973025049 | 32 | |
| 7 | 0.6223506743737958 | 32 | |
| koelectra | 8 | 0.5809248554913294 | 64 |
| 7 | 0.6936416184971098 | 64 | |
| ko-electra-v1 | 8 | 0.5240847784200385 | |
| 7 | 0.6425818882466281 | ||
| ko-electra-v2 | 8 | 0.5154142581888247 | |
| 7 | 0.6339113680154143 | ||
| train+ korean hate speech | |||
| electra-kor-base | 8 | 0.5154142581888247 | |
| 7 | 0.6416184971098265 | ||
| 대화별 문장 합친 | 데이터 | train_merge | |
| electra-kor-base | 8 | 0.1329479768786127 | '비도덕 아님'이 많이 삭제되서 |
| 7 | 0.14065510597302505 | 성능이 조금 떨어진듯 | |
앙상블 (Hard Voting)
- 5개의 모델 중 3개 이상 True로 나오면 True로 설정
- LSTM 의 경우 가장 높았던 성능
- 외부데이터 추가, 15 epoch